利用Heroku的指标获得更好的应用性能


今天,我们将讨论Rails和Heroku上与性能相关的项目。我想介绍Heroku指标仪表板,以及如何在此基础上对应用程序进行性能优化。
Heroku是一个平台即服务(PaaS)提供托管web应用程序,是最简单的服务之一,让你的应用程序快速上线。尽管它建在上面AWS在美国,它有许多功能,使得它比其他云计算服务更简单、更吸引人。其中一个这样的特性是它的度量仪表板,它提供了应用程序在基础设施级如何执行的见解。
在本教程中,我们将看到如何使用它来优化我们的Rails应用程序。
请注意,Heroku指标只在资源利用方面有帮助,比如CPU、内存和IO,但它对我们的应用程序性能没有太大帮助。有许多用于应用程序监视的工具,例如New Relic而且天窗.我强烈建议在使用Heroku指标的同时使用这些服务。
在本教程中,我们将首先看到指标指示板的概述,它提供了什么样的见解,以及您应该知道的一些重要的错误代码。然后,我们将构建一个带有两个表的示例Rails应用程序,并将其托管在Heroku上。
一旦托管,我们将超载我们的服务器,并看到Heroku指标显示我们的问题。在此基础上,我们将探索一些最佳实践,以进行微调,并查看修复的实际结果。
让我们开始吧。
Heroku Metrics概述
正如我们在上面看到的,Heroku度量提供了应用程序性能方面的见解。指标指示板将只对付费层的应用程序启用和访问。在Heroku中,您可以从应用程序页面访问应用程序的度量仪表板。
指示板
首先,让我们看看Heroku的仪表板提供的指标。默认情况下,Heroku为您的dynos收集以下指标。
内存使用情况
这提供了您的应用程序对进程类型的内存使用情况的洞察。该指标为您提供总内存使用量、交换使用量和内存配额。所有这些指标都是在动态级别上收集的。还有RSS,它是在所选进程类型上的所有dynos上的内存总量。
绝妙的负载
Dyno负载表示您的Dyno所招致的负载。这是队列中等待空闲dyno的CPU任务数。
事件
它表示应用程序中发生的事件和错误。部署、重新启动和扩展等事件都记录在这里。此外,它还捕获已经发生的错误。我们将在下面看看你经常会看到的一些重要错误。
虽然这些都是为所有dynos捕获的,但有几个指标仅为捕获的网络功率计。
响应时间
这显示了应用程序的平均响应时间和第95个百分位。第95百分位表示95%的应用程序请求的处理速度比指定的时间快。
吞吐量
这可以让我们了解应用程序在一分钟内收到的请求数量。它显示已成功处理的请求的数量和未成功处理的请求的数量。
错误
现在,让我们看看在仪表板上可能会遇到的一些重要错误代码。
R14和r15
臭名昭著的R14错误代码表示内存溢出问题。这意味着,您的应用程序使用的内存超过了dyno上的可用内存。当应用程序的内存需求超过配额时,Heroku开始提供交换内存,即存储在磁盘上的内存。但是,这会直接影响应用程序的响应时间。
出现这种情况的原因有很多,但更常见的情况是内存泄漏。如果您看到内存使用情况不断攀升,这很好地表明您的应用程序可能正在泄漏内存。
如果您的应用程序还没有停止消耗更多内存,则R15是紧随R14之后的错误代码。当出现此错误时,Heroku将自动重新启动应用程序。可以找到每个动态计划的配额在这里.
H10
这是一个您应该注意的错误代码,当发生这种情况时,您最好立即修复它。H10表示应用程序崩溃。大多数web服务器都有关于worker数量和静默重启崩溃的worker的配置。如果它没有为您的应用程序配置,或者如果您的应用程序是单线程/单工作者应用程序,则此错误代码意味着应用程序已关闭。
H12和h13
这些错误代码与请求/响应时间有关。H12在每次请求超时时被触发,这意味着需要超过30秒的时间才能返回响应。30秒的限制是在Heroku路由器级别。
H13也是一种请求超时,但它发生在应用程序内部。当你的web服务器有一个较低的请求超时阈值,比如10秒,而一个请求需要15秒来处理,连接将被你的web服务器关闭。这时,Heroku触发了H13。
上面提到的一些错误比其他错误更常见。他们的解释可以找到完整的错误代码列表在这里.
有了Heroku仪表板的基本概述之后,我想在上面讨论的基础上向您展示一个示例应用程序的优化。
样例应用程序
我们的示例应用程序将非常小而琐碎。可以通过以下命令生成:
Rails new heroku-metric -example -d postgresql rake db:create && rake db:migrate Rails g scaffold post title body:text railg scaffold comment body post:references rake db:migrate我刚刚创建了一个Rails应用程序,它有两个支架:帖子和评论。现在,我们将添加一个种子文件来生成用于测试的示例数据。这个步骤是可选的,但它只是为每个请求投入一些处理时间。我用的是骗子Gem生成种子数据。下面是种子文件的内容。
One hundred.次做|t|帖子=帖子.创建(标题:骗子::Lorem.词,身体:骗子::Lorem.段落(3.).加入(' '))把("创建的职位-#{帖子.id}")兰德(10.50).次做|c|评论=评论.创建(身体:骗子::Lorem.段,帖子:帖子)把("创建的评论-#{评论.id}的帖子#{帖子.id}")结束结束现在,让我们初始化git存储库并部署到Heroku:
Git初始化。git commit -m "Initial commit" heroku apps:create git push heroku master heroku run rake db:migrate heroku run rake db:seedRails应用程序现在已经成功部署到Heroku。让我们开始在应用程序中添加负载以生成一些指标。
在本教程中,我使用了Heroku的爱好dyno,它带有512 MB的RAM。这里有更多关于动态类型的信息在这里
请求超时
我使用围攻对服务器施加压力。下面是负载测试的当前设置。
siege -t 5M -c 30 https://rocky-coast-29518.herokuapp.com/posts -v在这里,我连续5分钟生成30个并发用户到posts端点。运行后,您可以使用Heroku指标看到它对应用程序的影响:

如您所见,请求开始很快超时。为什么?
首先也是最重要的原因是我们的web服务器。Rails默认带有WEBrick,这是Ruby的一个简单的HTTP服务器。它是而且应该主要用于发展目的。WEBrick是一个单线程的web服务器,不支持并发,所以一次只处理一个请求。为了解决这个问题,让我们配置一个不同的web服务器。
我们要用彪马这是Heroku推荐的web服务器。
添加web服务器非常简单。只需添加宝石“彪马”你的Gemfile和做包安装.
安装完成后,在下面创建puma配置文件配置/ puma.rb并添加下面的行。
工人整数(ENV[“工人”]||4)threads_count=整数(ENV[“线程”]||5)线程threads_count,threads_count preload_app!rackupDefaultRackup港口ENV[“端口”]||3000环境ENV[“RACK_ENV”]||“发展”on_worker_boot做ActiveRecord::基地.establish_connection结束我将工作人员计数从环境变量传递给工人方法,默认为4。然后在第3行,我将最小线程和最大线程都传递为5。在最后一个块上,当一个worker启动时,我正在建立一个活动记录连接。
配置完成后,创建一个名为Procfile在应用程序的根目录中添加下面的行,并将应用程序部署到Heroku。
bundle exec puma -C config/puma.rb部署完成后,我开始使用相同的规格进行负载测试。马上,我开始看到改善的结果。响应时间显著下降,记忆片段也是如此。我们还可以看到吞吐量的增加:
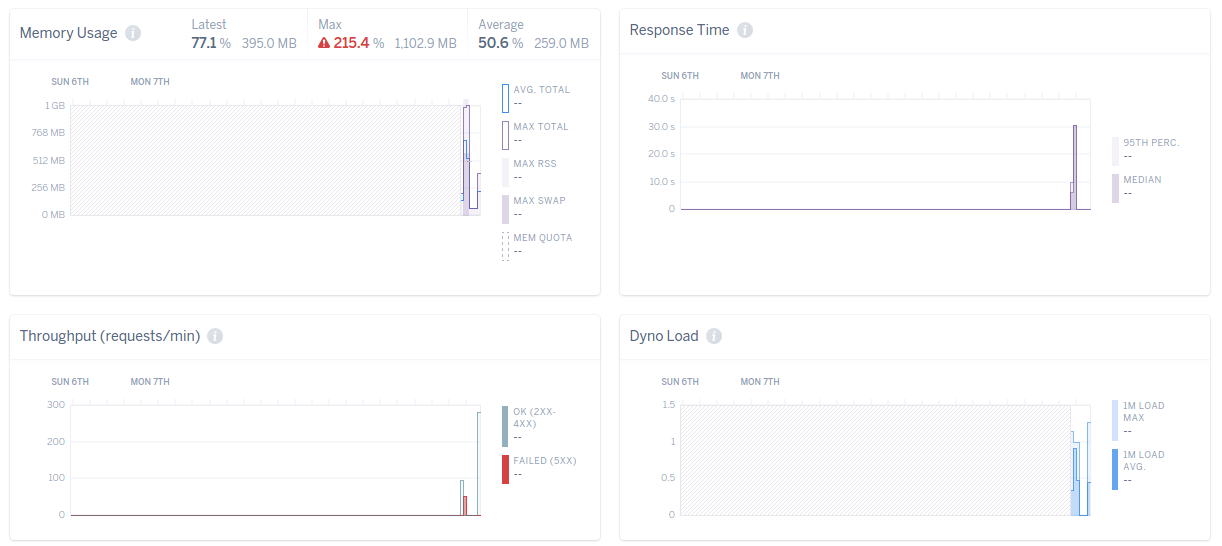
在更新我们的web服务器之后,我们看到应用程序的性能有了巨大的提高。
内存过载
我们的表现很好,但我们仍然可以从我们的资源中获得更多。查看这些图表,您可以看到我们只使用了可用内存的一半。
让我们在Heroku上更新工人数到5,线程数到10。让我们再次运行负载测试,这次使用更多并发用户。下面是更新后的负载测试配置。
siege -t 5M -c 200 https://rocky-coast-29518.herokuapp.com/posts -v我刚刚将并发用户从30个更新到200个!不,正如您所预料的那样,应用程序并没有崩溃。但我们确实重新开始使用我们的资源。吞吐量有所增加,但我们开始看到许多失败的请求和内存过载。
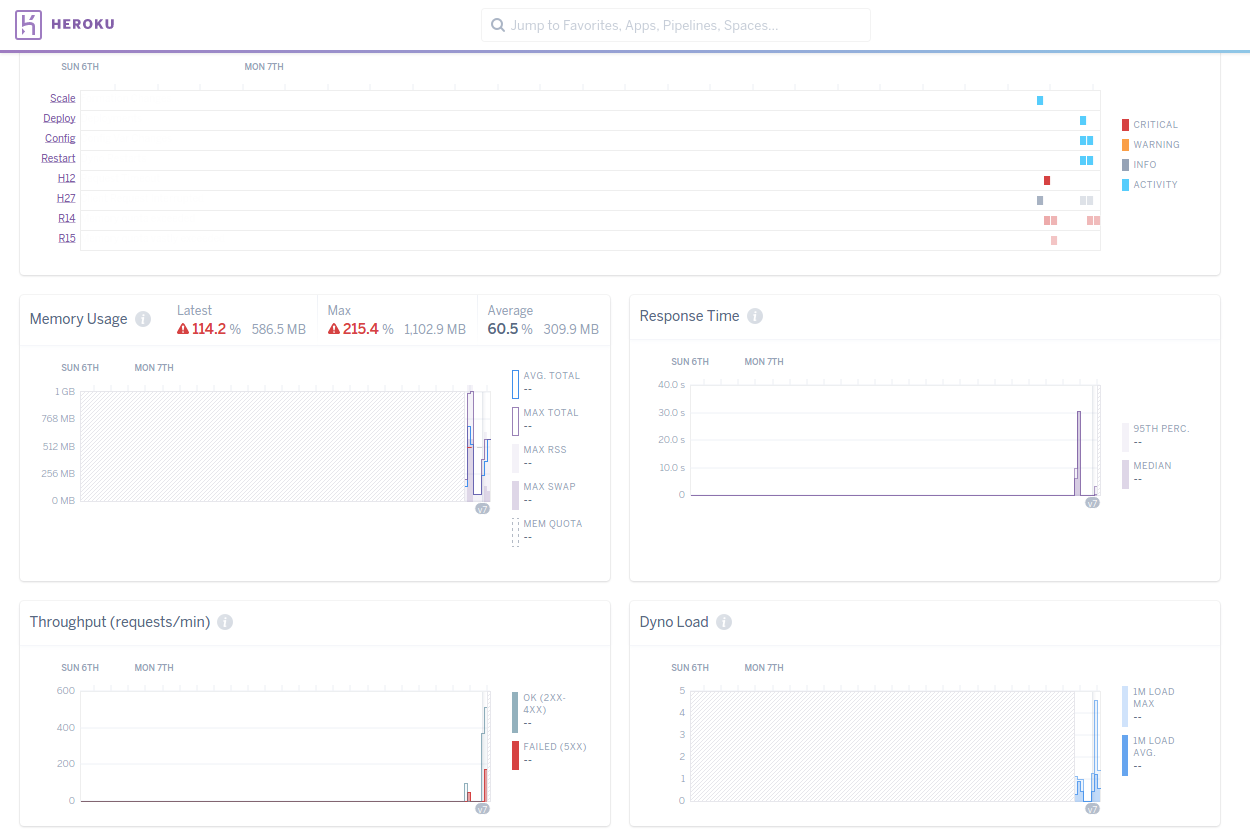
出现这种情况的原因有几个:
我们的工作线程设置不太正确。我们用了5个工人,每人10根线。但是本例中使用的DB计划最多只有20个连接。因此,有些线程没有获得DB连接,并在该阶段失败。
因为我们的worker计数更多的是内存大小,并且由于worker使用内存,我们开始看到r14。
为了解决这个问题,我将工人数更新为3,线程数更新为8。当我重新运行测试时,没有出现请求超时或内存过载。
作为我们在应用程序上施加的负载的副作用,响应时间增加了,吞吐量减少了一点。但是,在任何时候,缓慢的请求都比失败的请求要好。
在应用程序级别上也有一些事情可以修复。例如,/职位端点正在加载整个posts表,这是相当糟糕的,可以通过添加分页或延迟加载来修复。但是,我们在这里的重点是优化可用的资源。您可以了解更多关于Rails性能优化的知识在这里.
结论
正如我们所看到的,Heroku的应用程序指标对于优化Rails应用程序非常方便和有帮助。一些配置调整可以带来一些大的改进。
解决负载问题最常见的方法是提供更多的资源,这很好。但是,我仍然建议在投入更多资源之前,查看一下指标,看看应用程序是否真正利用了可用资源。
在上面讨论的步骤中,没有为worker或线程数设置一个标准值,因为它与应用程序、动态大小和服务(例如:DB)约束有关。我建议对其进行调整,直到您能够在资源使用与吞吐量和响应时间之间找到平衡。
此处使用的示例应用程序可在github.
感谢阅读!






