网页抓取初学者

随着电子商务的蓬勃发展,近年来我成了比价应用程序的粉丝。我在网上(甚至是线下)购买的每一件商品都是在提供该产品的网站上进行彻底调查的结果。
我使用的一些应用程序包括RedLaser、ShopSavvy和BuyHatke,它们在提高透明度和节省消费者时间方面做得很好。
你有没有想过这些应用程序是如何获得这些重要数据的?在大多数情况下,应用程序采用的流程是网页抓取.
Web抓取的定义

网络抓取是指从网络上提取数据的过程。使用正确的工具,可以提取任何可见的内容。在这篇文章中,我们将专注于编写程序,使这一过程自动化,并帮助您在相对较短的时间内收集大量数据。除了我已经给出的例子,抓取还有很多用途,比如搜索引擎优化跟踪,工作跟踪,新闻分析,以及——我最喜欢的——社交媒体上的情绪分析!
注意事项
在你开始网络抓取冒险之前,确保你意识到涉及的法律问题。许多网站在他们的服务条款中特别禁止抓取。例如,引用媒介,“如果按照robots.txt文件的规定执行,则允许抓取服务,但禁止抓取服务。”不允许抓取的抓取网站实际上可能会让你被列入黑名单!就像任何其他工具一样,网络抓取可以用于复制其他网站的内容等原因。抓取也导致了许多诉讼。
设置代码
现在您知道我们必须小心行事,让我们进入刮痧。抓取可以在任何编程语言中完成,而我们为Node覆盖它有段时间了。在这篇文章中,我们将使用Python,因为语言的简单性和包的可用性使这个过程变得容易。
潜在的过程是什么?
当你在互联网上访问一个网站时,你实际上是在下载HTML代码,它由你的网络浏览器分析和显示。这个HTML代码包含了所有可见的信息。因此,可以通过分析此HTML代码获得所需的信息(如价格)。您可以使用正则表达式搜索大海捞针,或者使用库解析HTML并获得所需的数据。
在Python中,我们将使用一个名为美丽的汤来分析这个HTML数据。您可以通过安装程序安装模块,如皮普运行命令如下:
皮普安装beautifulsoup4或者,您可以从源代码构建它。安装步骤列在模块的文档页面.
安装完成后,我们将大致遵循以下步骤:
- 发送一个请求到URL
- 接收响应
- 分析响应以找到所需的数据。
为了演示,我们将使用我的博客必威滚http://dada.the必威滚blogbowl.in/.
前两步相当简单,可以通过以下方式完成:
从urllib导入urlopen #发送http请求网页= urlopen('http://my_website.com/').read()接下来,我们需要提供对的响应
从bs4导入BeautifulSoup #做汤!美味的;)soup = BeautifulSoup(网页,"html5lib")注意我们用了html5lib作为我们的解析器。如上所述,您可以为BeautifulSoup安装不同的解析器他们的文档.
解析HTML
现在我们已经为BeautifulSoup提供了HTML,让我们来看看几个命令。为了检查我们是否有正确的HTML标记,让我们验证页面的标题(在Python解释器上):
> > >汤。title Transcendental Tech Talk
>>> soup.title.text u'Transcendental Tech Talk' >>>接下来,我们继续从页面中提取特定元素。假设我想提取我的博客上的文章标题列表。必威滚为此,我需要分析HTML结构,这是我通过Chrome检查器完成的(右键单击一个项目并选择“检查元素”)。其他浏览器中也有类似的工具。
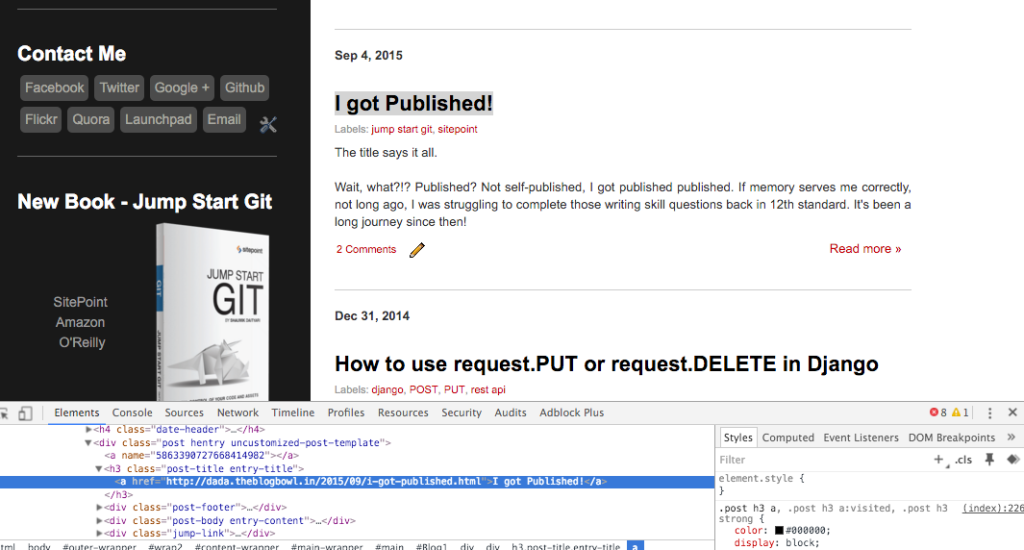
使用Chrome检查器检查页面的HTML结构
如您所见,所有标题都放在h3标签,有两个类-文章标题而且条目标题.搜索所有h3类中的元素文章标题应该能给我那页上的标题列表。我们使用find_all的功能,并使用class_参数指定我们的类:
>>>标题=汤。find_all('h3', class_ = 'post-title') #Getting all titles >>> titles[0].text u'\nKolkata #BergerXP IndiBlogger meet, Marketing Insights, and some Blogging Tips\n' >>>通过使用类搜索项目也可以获得相同的结果文章标题:
>>>标题=汤。find_all(class_ = 'post-title') #Getting all items with class post-title >>> titles[0].text u'\nKolkata #BergerXP IndiBlogger meet, Marketing Insights, and some Blogging Tips\n' >>>如果您对进一步探索项目的链接感兴趣,您可以运行以下命令:
>>> for title in titles:……#每个标题以 < a href =…>职位Title…Print title.find("a").get("href")…http://dada.the必威滚blogbowl.in/2015/09/kolkata-bergerxp-indiblogger-meet.html http://dada.theblogbowl.in/2015/09/i-got-published.html http://dada.theblogbowl.in/2014/12/how-to-use-requestput-or-requestdelete.html http://dada.theblogbowl.in/2014/12/zico-isl-and-atk.html…>>> 在BeautifulSoup中有许多内置的方法来在HTML中导航,其中一些如下所示:
> > >标题[0]。content [u'\n', Kolkata #BergerXP IndiBlogger meet, Marketing Insights, and some Blogging Tips, u'\n'] >>>请注意,您也可以使用孩子们属性,但它充当一台发电机:
> > >标题[0]。>\n\n\n加尔各答#BergerXP IndiBlogger…>>>
您也可以使用正则表达式来搜索CSS类,如中所述的文档.
使用Mechanize模拟登录
到目前为止,我们所做的基本上是下载一个页面并分析其内容。然而,web开发人员可能通过非浏览器阻止了请求,或者网站的一部分可能只有在登录后才能访问。那么我们应该如何进行这个过程呢?
在第一种情况下,当我们向页面发送请求时,我们需要模拟浏览器。每个HTTP请求都有一些相关的头信息,包括访问者的浏览器、操作系统和屏幕大小等信息。我们可以操纵它,使它看起来像浏览器在发送请求。
在第二种情况下,我们需要登录网站并使用cookie维护会话,以便访问限制区域。让我们看看如何在模拟浏览器的同时做到这一点。
我们将使用模块cookielib使用cookie管理会话。此外,我们将使用用机械装置,可以通过安装程序安装皮普.
我们将通过这个页面登录博客碗必威滚,然后访问我们的通知页面.代码通过注释内联解释:
import mechanize import cookielib from urllib import urlopen from bs4 import BeautifulSoup # CookieJar cj = cookielb . lwpcookiejar () browser = mechanize. browser () browser.set_cookiejar(cj) browser.set_handle_robots(False) browser.set_handle_redirect(True) #解决问题#1通过添加HTTP头浏览器模拟浏览器。addheaders = [('User-agent', 'Mozilla/5.0 (X11;U;Linux i686;en - us;rv:1.9.0.1) Gecko/2008071615 Fedora/3.0.1-1。fc9 Firefox/3.0.1')] #打开登录页面浏览器。Open ("http://theblogbowl.in/lo必威滚gin/") #选择登录表单(页面的第一个表单)浏览器。select_form(nr = 0) #浏览器。select_form(name = "form_name") #表单的第一个标记是一个CSRF令牌#设置第2和第3标记为电子邮件和密码browser.form.set_value("email@example.com", nr=1) browser.form. form.set_value("email@example.com", nr=1)set_value("password", nr=2) #登录response = browser.submit() #登录后打开新页面soup = BeautifulSoup(browser.open('http://theblogbowl.in/notifications/').rea必威滚d(), "html5lib")
通知页面的结构
打印通知打印汤。查找(class_ = "search_results").text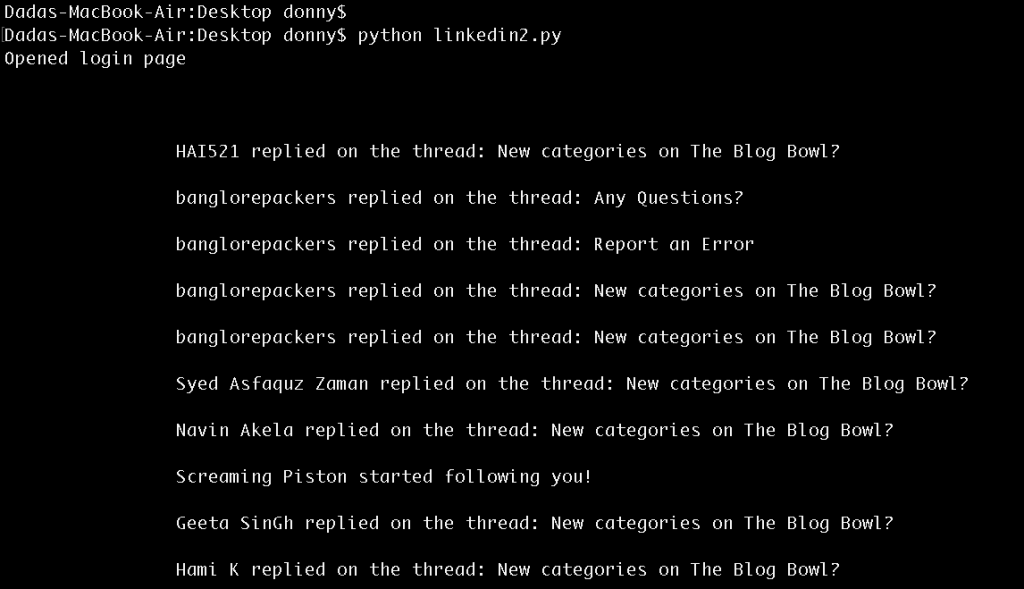
登录通知页面的结果
最后的话
正如许多开发者会告诉你的那样,你在网上看到的任何东西都可能被窃取。通过这篇文章,您知道登录背后的一些东西也可以很容易地提取出来。在你的IP被阻止的情况下,你可以屏蔽你的IP地址(或使用一个不同的)。为了让它看起来像是有人正在访问数据,您也可以在请求之间保持一个时间延迟。
随着对数据需求的增加,网络抓取(出于好的和坏的原因)在未来只会增加。因此,建议您了解这个过程,以便有效地使用它或将自己从它中拯救出来!




