Node.js事件循环:概念和代码的开发者指南

异步在任何编程语言中都是困难的。像并发性、并行性和死锁这样的概念即使是最有经验的工程师也会不寒而栗。当存在bug时,异步执行的代码是不可预测的,并且难以跟踪。这个问题是不可避免的,因为现代计算是多核的。CPU的每一个核心都有一个热量限制,没有什么能更快。这给开发人员带来了压力,要求他们编写有效的代码来利用硬件。
JavaScript是单线程的,但这是否限制了Node使用现代架构?最大的挑战之一是处理多线程,因为它固有的复杂性。旋转新线程并在两者之间管理上下文切换是昂贵的。操作系统和程序员都必须做大量工作来交付具有许多边缘情况的解决方案。在这篇文章中,我将向您展示Node如何通过事件循环处理这个困境。我将探索Node.js的每个部分事件循环并演示它是如何工作的。Node的“杀手级应用”特性之一就是这个循环,因为它以一种全新的方式解决了一个难题。
什么是事件循环?
事件循环是一个单线程、非阻塞的异步并发循环。对于那些没有计算机科学学位的人来说,想象一下一个进行数据库查询的web请求。一个线程一次只能做一件事。它不等待数据库响应,而是继续拾取队列中的其他任务。在事件循环中,主循环展开调用堆栈,不等待回调。因为循环不会阻塞,所以它可以自由地同时处理多个web请求。多个请求可以同时进入队列,这使得它具有并发性。循环不会等待从一个请求到完成的所有事情,而是在它们来的时候不阻塞地拾取回调。
循环本身是半无限的,这意味着如果调用堆栈或回调队列为空,它可以退出循环。可以将调用堆栈看作是展开的同步代码,例如console.log,然后循环轮询更多的工作。Node在后台使用libuv轮询操作系统以获取来自传入连接的回调。
您可能想知道,为什么事件循环在单个线程中执行?对于每个连接所需的数据,线程在内存中相对较重。线程是向上旋转的操作系统资源,不能扩展到数千个活动连接。
多条线索通常也会使故事复杂化。如果回调返回数据,它必须将上下文封送回执行线程。线程之间的上下文切换很慢,因为它必须像调用堆栈或本地变量一样同步当前状态。当多个线程共享资源时,事件循环会粉碎错误,因为它是单线程的。单线程循环削减线程安全边缘情况,可以更快地切换上下文。这才是循环背后真正的天才。它有效地利用连接和线程,同时保持可伸缩性。
足够的理论;现在来看看代码是什么样子的。在REPL或下载源代码.
半无限循环
事件循环必须回答的最大问题是循环是否存在。如果是,它计算出在回调队列上等待多长时间。在每次迭代中,循环展开调用堆栈,然后轮询。
下面是一个阻塞主循环的例子:
setTimeout(()= >控制台.日志('来自回调队列的Hi '),5000);//让循环持续这么长时间常量stopTime=日期.现在()+2000;而(日期.现在()<stopTime){}//阻塞主循环如果运行这段代码,请注意循环会阻塞两秒钟。但是循环一直保持活跃,直到回调在5秒内执行。一旦主循环解除阻塞,轮询机制就会计算出它在回调上等待的时间。当调用堆栈展开且不再剩下回调时,此循环终止。
回调队列
现在,当我阻塞主循环,然后安排回调时,会发生什么?一旦循环被阻塞,它就不会在队列上放更多的回调:
常量stopTime=日期.现在()+2000;而(日期.现在()<stopTime){}//阻塞主循环//执行时间为7秒setTimeout(()= >控制台.日志(Ran回调A),5000);这次循环持续7秒。事件循环很简单。它无法知道将来会有什么东西排队。在真实的系统中,传入的回调被排队,并在主循环可以自由轮询时执行。事件循环经过几个阶段按顺序当它被打开的时候。所以,为了在关于循环的面试中取得好成绩,避免使用花哨的术语,如“事件发射器”或“反应堆模式”。它是一个简单的单线程循环,并发的,非阻塞的。
async/await的事件循环
为了避免阻塞主循环,一个想法是在async/await周围包装同步I/O:
常量fs=需要(“fs”);常量readFileSync=异步(路径)= >等待fs.readFileSync(路径);readFileSync(“readme.md”).然后((数据)= >控制台.日志(数据));控制台.日志(“事件循环继续没有阻塞……”);之后的任何东西等待来自回调队列。代码读起来像同步阻塞代码,但它并没有阻塞。注意async/await makesreadFileSyncthenable,这样它就脱离了主循环。想想接下来发生的事情等待作为非阻塞通过回调。
完全披露:上面的代码仅用于演示目的。我建议在实际代码中使用fs.readFile,它会触发一个可以封装在承诺周围的回调。一般的意图仍然有效,因为这将阻塞I/O从主循环中移除。
更进一步
如果我告诉您,事件循环比调用堆栈和回调队列有更多内容,会怎样?如果事件循环不是一个而是多个呢?如果它可以有多个线程呢?
现在,我想带您深入了解Node内部结构。
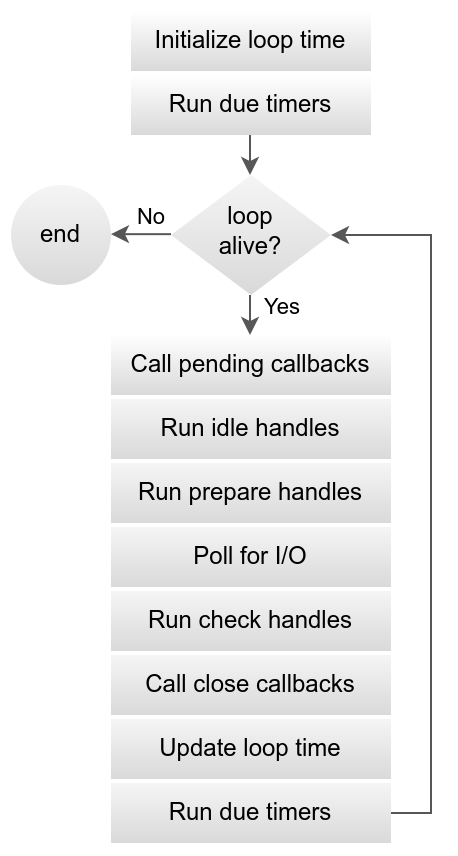
事件循环阶段
这些是事件循环阶段:

图片来源:libuv文档
- 时间戳被更新。事件循环在循环开始时缓存当前时间,以避免频繁的与时间相关的系统调用。这些系统调用是libuv内部的。
- 循环是活的吗?如果循环有活动句柄、活动请求或关闭句柄,则它是活动的。如所示,队列中的挂起回调使循环保持活动状态。
- 到期计时器执行。这就是
setTimeout或setInterval回调。循环检查缓存现在执行过期的活动回调。 - 队列中的挂起回调执行。如果之前的迭代延迟了任何回调,这些回调将在此时运行。轮询通常立即运行I/O回调,但也有例外。这一步处理来自前一次迭代的任何掉队者。
- 空闲处理程序执行-主要是由于糟糕的命名,因为这些在每次迭代中运行,并且是libuv内部的。
- 准备手柄
setImmediate循环迭代中的回调执行。这些句柄在循环阻塞I/O之前运行,并为这个回调类型准备队列。 - 计算轮询超时。循环必须知道它为I/O阻塞了多长时间。这是它计算超时的方式:
- 如果循环即将退出,则timeout为0。
- 如果没有活动句柄或请求,则timeout为0。
- 如果有空闲句柄,则timeout为0。
- 如果队列中有任何句柄挂起,则timeout为0。
- 如果有关闭句柄,则timeout为0。
- 如果以上都不是,则超时设置为最接近的计时器,或者如果没有活动计时器,∞.
- 循环阻塞I/O与前一阶段的持续时间。队列中与I/O相关的回调在此时执行。
- 检查句柄回调是否执行。这个阶段是
setImmediate运行,它与准备句柄对应。任何setImmediate在I/O回调执行中排队的回调在这里运行。 - 执行关闭回调函数。这些是从关闭的连接释放的活动句柄。
- 迭代结束。
您可能想知道为什么要为I/O轮询块,而它应该是非阻塞的?只有当队列中没有挂起的回调并且调用堆栈为空时,循环才会阻塞。在Node中,最近的计时器可以通过setTimeout例如。如果设置为无穷大,则循环等待传入的连接并执行更多的工作。这是一个半无限循环,因为当没有其他事情可做且存在活动连接时,轮询将使循环保持活跃。
下面是这个超时计算的Unix版本:
intuv_backend_timeout(常量uv_loop_t*循环){如果(循环->stop_flag! =0)返回0;如果(!uv__has_active_handles(循环)& &!uv__has_active_reqs(循环))返回0;如果(!QUEUE_EMPTY(&循环->idle_handles))返回0;如果(!QUEUE_EMPTY(&循环->pending_queue))返回0;如果(循环->closing_handles)返回0;返回uv__next_timeout(循环);}你可能对C语言不太熟悉,但这读起来像英语,并且做的完全是第七阶段的事情。
逐阶段演示
用纯JavaScript显示每个阶段:
/ / 1。循环开始,时间戳被更新常量http=需要(“http”);/ / 2。如果调用堆栈中有要unwind的代码,则循环将保持活动状态/ / 8。轮询I/O并从传入连接执行此回调常量服务器=http.createServer((要求的事情,res)= >{//网络I/O回调在轮询后立即执行res.结束();});//如果有打开的连接,则保持循环活动/ / 7。如果没有事情要做,就计算超时服务器.听(8000);常量选项={//避免DNS查找以远离线程池主机名:“127.0.0.1”,港口:8000};常量sendHttpRequest=()= >{//网络I/O回调在阶段8运行//文件I/O回调在阶段4运行常量要求的事情=http.请求(选项,()= >{控制台.日志('从服务器收到的响应');/ / 9。执行检查句柄回调setImmediate(()= >/ / 10。关闭回调执行服务器.关闭(()= >//结束。剧透!循环在最后死亡。控制台.日志(“关闭服务器”)));});要求的事情.结束();};/ / 3。计时器在8秒内运行,同时循环保持活跃//轮询之前计算的超时使它保持活动setTimeout(()= >sendHttpRequest(),8000);/ / 11。迭代结束因为文件I/O回调在阶段4中运行,在阶段9之前运行setImmediate ()先开火:
fs.readFile(“readme.md”,()= >{setTimeout(()= >控制台.日志('文件I/O回调通过setTimeout()'),0);//首先执行这个回调函数setImmediate(()= >控制台.日志('通过setimmediation()文件I/O回调'));});没有DNS查找的网络I/O比文件I/O代价更低,因为它在主事件循环中执行。文件I/O通过线程池进行排队。DNS查找也使用线程池,因此这使得网络I/O与文件I/O一样昂贵。
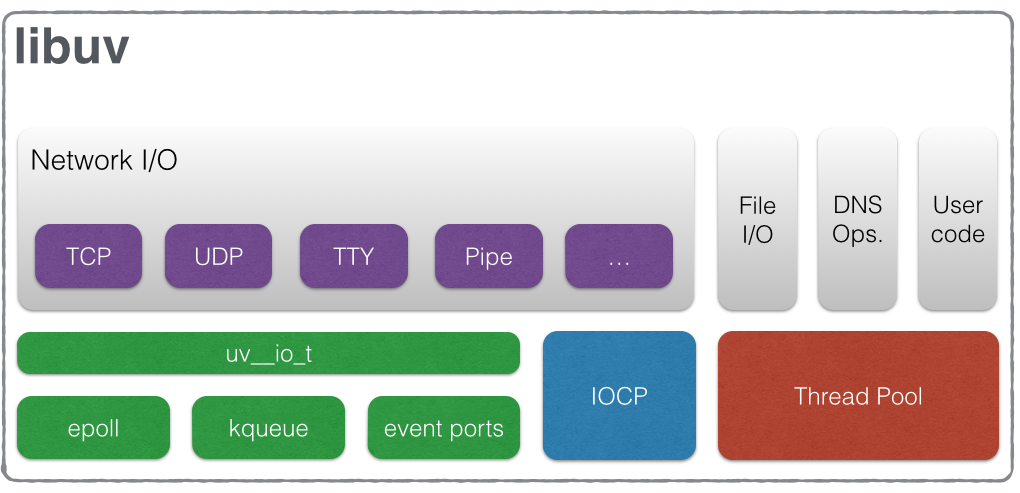
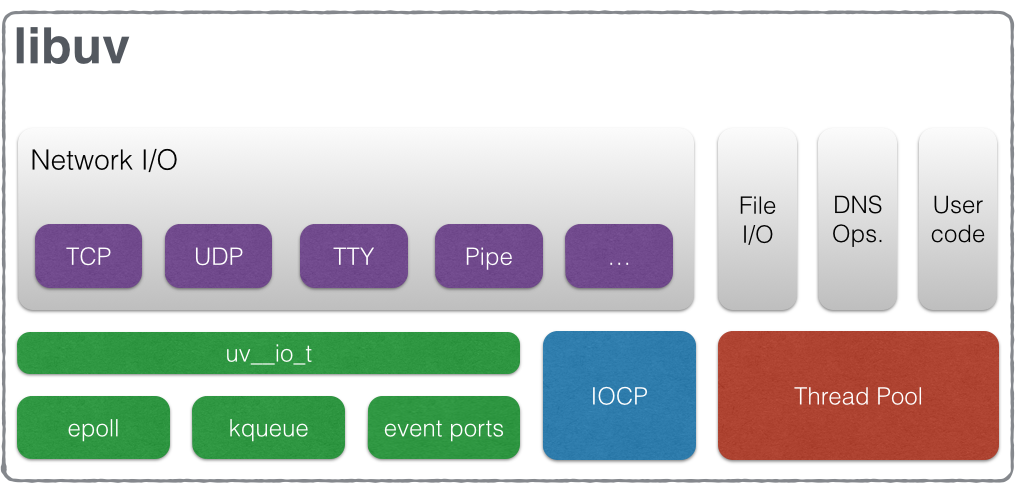
线程池
节点内部有两个主要部分:V8 JavaScript引擎和libuv。文件I/O、DNS查找和网络I/O都是通过libuv实现的。
这是整体架构:
图片来源:libuv文档
对于网络I/O,事件循环在主线程内部轮询。这个线程不是线程安全的,因为它不与另一个线程进行上下文切换。文件I/O和DNS查找是特定于平台的,因此方法是在线程池中运行它们。一种想法是自己进行DNS查找,以远离线程池,如上面的代码所示。输入IP地址与本地主机,例如,将查找从池中取出。线程池的可用线程数量有限,可以通过UV_THREADPOOL_SIZE环境变量。默认的线程池大小大约是4。
V8在单独的循环中执行,耗尽调用堆栈,然后将控制权交还给事件循环。V8可以在自己的循环之外使用多个线程进行垃圾收集。可以把V8看作是接收原始JavaScript并在硬件上运行的引擎。
对于普通程序员来说,JavaScript仍然是单线程的,因为没有线程安全。V8和libuv内部程序各自启动各自的线程来满足各自的需求。
如果Node中存在吞吐量问题,请从主事件循环开始。检查应用程序完成一次迭代所需的时间。应该不会超过100毫秒。然后,检查线程池是否耗尽,以及可以从线程池中清除哪些内容。也可以通过环境变量来增加池的大小。最后一步是在V8中对同步执行的JavaScript代码进行微基准测试。
结束
当回调进入队列时,事件循环继续迭代每个阶段。但是,在每个阶段都有一种方法来排队另一种类型的回调。
process.nextTick ()vssetImmediate ()
在每个阶段结束时,循环执行process.nextTick ()回调。注意,此回调类型不是事件循环的一部分,因为它在每个阶段的末尾运行。的setImmediate ()回调是整个事件循环的一部分,所以它并不像名字所暗示的那样立即。因为process.nextTick ()需要熟悉事件循环,我建议使用setImmediate ()一般来说。
您可能需要这样做的原因有几个process.nextTick ():
- 允许网络I/O处理错误、清理或在循环继续之前再次尝试请求。
- 可能有必要在调用堆栈展开后但在循环继续之前运行回调。
例如,一个事件发射器希望在它自己的构造函数中触发一个事件。在调用事件之前,调用堆栈必须先展开。
常量EventEmitter=需要(“事件”);类ImpatientEmitter扩展EventEmitter{构造函数(){超级();//在阶段结束时使用一个未展开的调用堆栈触发此函数过程.nextTick(()= >这.发出(“事件”));}}常量发射器=新ImpatientEmitter();发射器.在(“事件”,()= >控制台.日志(“发生了一件急躁的事!”));允许调用堆栈展开可以防止类似的错误RangeError:超过最大调用堆栈大小.你要做的就是确保process.nextTick ()不会阻塞事件循环。同一阶段内的递归回调调用可能会出现阻塞问题。
结论
事件循环在其终极复杂程度上是简单的。它需要解决一些难题,比如异步、线程安全性和并发性。它会删除没有帮助或不需要的内容,并以最有效的方式最大化吞吐量。正因为如此,Node程序员花更少的时间追踪异步错误,而花更多的时间交付新功能。





{kind=link}
{kind=link}