Redwood是一个全栈、无服务器的Jamstack框架

想象一下,一个React应用程序,由CDN交付,将GraphQL查询发送到世界各地运行AWS Lambdas的后端,所有这些都可以通过a访问git推.这就是Redwood——一个固执己见的全栈框架<一个style="font-weight:bold" href="//www.shaoxingby.com/learn-jamstack/">的Jamstack.
Redwood填补了JavaScript社区已经缺失了一段时间的需求——在一个新工具出现的速度已经成为一种文化基因的生态系统中,这不是一件容易的事情。这个全栈JavaScript解决方案为开发人员提供了极好的体验,旨在将Rails的独立的、脚手架驱动的开发理念引入到Jamstack站点提供的快速、安全的体验中。
Redwood希望成为一种能够打破Jamstack静态限制的工具,并将这种体验用于更加复杂的项目。
Redwood框架背后的思想体现在名称本身。红杉是北加州的一种树。它们是世界上最高的大树,有的高达380英尺(约116米)。现存最古老的红杉大约在3200年前从地面发芽。红木松果出奇的小。这些树可以防火,远看看起来很复杂,但近看仍然很简单。这就是框架试图实现的目标——为开发人员提供一种方法来构建漂亮的、密集的、有弹性的、易于使用的应用程序。
在本教程中,我将好好看看Redwood及其带来的好处。我假设对React、GraphQL和Jamstack有一定的熟悉。如果您想继续学习,可以找到完整的演示<一个href="https://github.com/sitepoint-editors/getting-started-redwood-js">GitHub上的示例代码.本教程将构建一个CRUD应用程序(创建-读取-更新-删除),并展示在Redwood中这是如何无缝的。
初始设置
为了成功安装Redwood,该工具检查以下版本要求:
- 节点:> = 12
- 纱:> = 1.5
假设Node为<一个href="//www.shaoxingby.com/quick-tip-multiple-versions-node-nvm/">可通过NVM获取,例如,安装Yarn vianpm:
npm安装- g纱所有Redwood命令都使用Yarn,这是必需的。启动你的第一个应用程序:
纱创建redwood-app入门-redwood-js这是终端的初始输出:
确保目标目录是一个新的或空的文件夹,否则此Yarn命令将失败。切换到这个新目录并启动开发服务器:
cdgetting-started-redwood-js纱红杉dev哈!这将自动打开设置为的浏览器http://localhost:8910.你的新项目应该是这样的:
继续,让开发服务器继续运行。需要重启的时候我会告诉你的。接下来,随着最初的Redwood项目到位,是时候提交进度了:
git初始化git添加.gitcommit - m“第一次提交”你可以随意在骨架项目里打探一下。应该有一个.gitignore文件,您可以在其中添加任何想要忽略的文件。例如,最初的框架项目具有node_modules文件夹在这个文件中。任何不在这个文件中的东西都会被提交到回购。
现在,深呼吸一下,欣赏一下这个工具是如何完成框架项目的大部分工作的。有两个感兴趣的文件夹-网络而且api-这似乎暗示了这个项目的后端和前端。有一个Babel和一个GraphQL配置文件表明它们是依赖关系。
在初始项目运行后,返回并查看控制台输出。应该有一条消息说“正在查看文件。api / src /功能”。这表明任何后端代码更改都会通过这个webpack文件监控器自动刷新。
红木文件夹结构
在文件资源管理器或您喜欢的代码编辑器中打开Redwood项目,并查看文件夹结构。忽略非必要文件,它具有以下层次结构:
┳┣━译译API┃┣━译译db┃┃┣━━schema。棱镜┃┃┗━━seed.js┃┗━┓src┃┣━┓功能┃┃┗━━graphql.js┃┣━━graphql┃┣━┓自由┃┃┗━━db.js┃┗━━服务┗━┓web┣━┓┃公众┣━━favicon.png┃┣━━README。md┃┗━━robots . txt┗━┓src┣━━组件┣━━布局┣━┓┃页面┣━┓FatalErrorPage┃┃┗━━FatalErrorPage.js┃┗━┓NotFoundPage┃┗━━NotFoundPage.js┣━━index.css┣━━index . html┣━━index.js┗━━Routes.js根源在于网络而且api分隔前端和后端代码的文件夹。Redwood将其称为“边”,Yarn将其称为“工作区”。
的api文件夹包含以下子目录:
db,其中包含数据库:schema.prisma具有包含表和列的数据库模式定义。seed.js最初使用任何零配置数据填充数据库。
数据库迁移在SQLite中,是框架的一部分。在我添加数据库后,将会有一个dev.db文件和一个名为迁移.这就是Redwood在项目中跟踪数据库模式更改的方法。
src拥有所有后端代码:功能:这些将有Lambda函数和graphql.js由Redwood生成的文件。graphql:这是用模式定义语言(SDL)编写的GraphQL模式。自由有一个文件db.js用来设置Prisma数据库。此文件夹用于存放不合适的代码功能或服务.服务:用于处理数据的业务逻辑。查询或更改数据的代码放在这里。
对于前端,请查看网络目录:
公共拥有React中没有的所有静态资产。这个文件夹中的所有文件都按原样复制:favicon.png:当页面第一次打开时,浏览器选项卡上会弹出一个图标。robots . txt控制网络爬虫搜索引擎优化。README.md解释如何以及何时使用此公用文件夹。src有几个子目录:组件拥有传统的React组件和Redwood cell(稍后会详细介绍)。布局:跨Pages共享的HTML/组件。在项目中,布局是可选的。页面有可能被包装在布局内的组件,并成为url的着陆页。例如,/作者映射到一个页面,每个页面路由都有自己的文件夹。NotFoundPage / NotFoundPage.js:当不存在页面时,框架服务于此页面(请看Routes.js下文)。FatalErrorPage / FatalErrorPage.js在应用程序中呈现未捕获的错误异常。
index.css:一个通用的地方来放置全局CSS,不属于其他任何地方。index . html:反应初始页面。index.js:引导代码让应用程序启动和运行。Routes.js:将URL映射到Page的路由定义。
在Routes.js文件,这是应用程序如何路由到NotFoundPage:
<路由器><路线notfound页面={NotFoundPage}/></路由器>创建作者数据库
对于这个应用程序,我将构建一个CRUD应用程序,在页面上显示作者列表。每个作者都有姓名、时间戳和他们最喜欢的主题等信息。为了保持简单,表有一个带有顺序整数的代理主键。想象一个作者数据库有以下列:
id:该作者的顺序唯一标识符的名字主题:作者最喜欢的话题createdAt:该记录的时间戳
Redwood使用Prisma ClientJS通过ORM查询构建器与数据库对话。Prisma客户端有另一个名为Migrate的工具,可以一致地更新数据库模式。对模式的每次更改都是一次迁移,并且<一个href="https://www.prisma.io/docs/concepts/components/prisma-migrate">棱镜迁移创建一个以改变数据库。Prisma支持最流行的SQL风格,如SQLite、MySQL和PostgreSQL。在本教程中,为了保持简单,我将以SQLite为目标。
开放api / db / schema.prisma并定义一个作者表格确保销毁此文件中的任何示例代码,因为它将在迁移中运行。
例如:
datasource DS {provider = "sqlite" url = env("DATABASE_URL")} generator client {provider = "prisma-client-js" binaryTargets = "native"} model Author {id Int @id @default(autoincrement()) name String email String @唯一主题字符串?createdAt DateTime @default(now())}它定义了一个包含以下列的表:
- 一个
id: Prisma使用@ id与其他表和@default值是顺序的自动增量()价值 - 一个
的名字定义为字符串类型 - 一个
@unique电子邮件定义为字符串 - 一个可选的
字符串?列名为topic - 一个时间戳
createdAt列设置为DateTime这将@default来现在()
继续,并将其作为迁移进行快照。确保在项目的根目录运行这个Yarn命令:
纱Redwood数据库保存创建作者这将创建一个名为“create authors”的迁移。Redwood并不关心名字是什么,因为这是为其他开发人员准备的。完成后,在其中查找一个新文件夹api / db /迁移带有此迁移的时间戳和名称。终端的输出将包含这个名称和它生成的文件。模式的快照已经存在schema.prisma,并且应用迁移的指令已经进入steps.json.
现在让我们应用数据库更改:
纱Rw db up注意简写的用法rw而不是红木.
数据库成型后,是时候转向UI了。Redwood有脚手架,可以很快得到一个基本的CRUD应用程序:
纱Rw g脚手架作者终端输出此应用程序生成的文件。如果您让开发服务器运行,请注意浏览器现在指向404 Not Found。将浏览器指向http://localhost:8910/authors要查看有什么可用的:
这就是使用脚手架CSS的骨架UI的样子。如果页面缺少样式,请打开index.js并添加进口的。/ scaffold.css ':
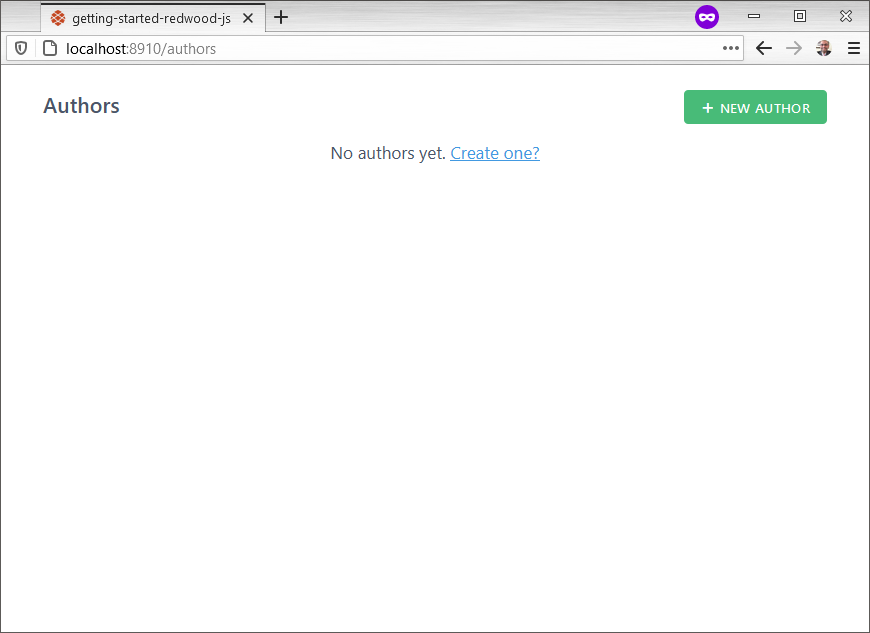
脚手架使所有的领域在作者表必需,尽管topic是可选列。要解决这个问题,打开web / src /组件/ AuthorForm / AuthorForm.js替换主题文本框用这个:
<文本框的名字=“主题”defaultValue={道具.作者?.主题}类名称=“rw-input”/>要查看Jamstack的运行情况,请在浏览器中打开开发人员工具并开始查看。我将用我的名字创建一个作者,没有最喜欢的主题(这是可选的)。然后,用我最喜欢的话题更新记录。网络流量将显示Ajax请求后端完成所有工作,而不需要任何完整的页面刷新。请确保禁用缓存以查看所有网络流量。
这是浏览器的样子:
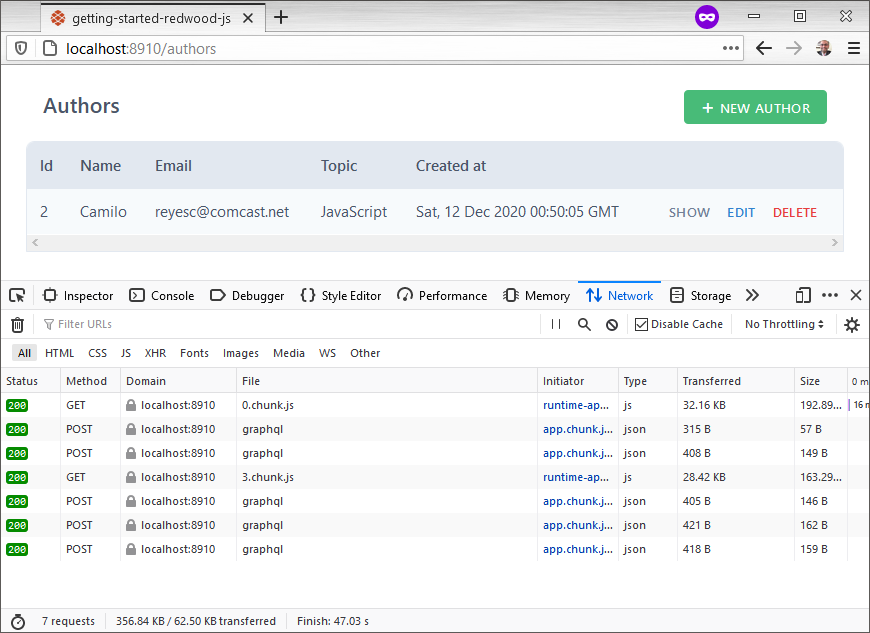
有几点需要注意。chunk.js请求是在浏览器中呈现应用程序部分内容的部分页面加载。这是React和webpack的实际应用。JSON网络请求具有GraphQL有效负载帖子查询或改变后端的数据。
打开网络请求有效负载会显示GraphQL查询。例如:
{“operationName”:“作者”,“变量”:{},“查询”:"查询author {AUTHORS {id name email topic createdAt __typename}}"}唷,所以红木创建所有的页面与很少的代码。不需要从头开始编写复杂的SQL或React组件。这就是红木的意思支架.
这是当我运行纱线机架作者命令:
- 一个SDL文件,其中定义了几个GraphQL查询和突变
api / src / graphql / authors.sdl.js - 中的服务文件
api / src /服务/作者/ authors.js使Prisma调用与数据库一起工作 - 一个Jest测试文件
api / src /服务/作者/ authors.test.js编写单元测试(稍后会详细介绍) - 几页
网络/ src /页面 EditAuthorPage编辑作者AuthorPage以显示一个作者的详细信息AuthorsPage获取所有作者NewAuthorPage创建作者- 这些页面的路由
网络/ src / Routes.js - 一个布局在
网络/ src /布局/ AuthorsLayout / AuthorsLayout.js - 细胞在
web / src /组件 AuthorCell只有一个作者AuthorsCell获取作者列表EditAuthorCell获取要在数据库中编辑的作者- 组件也在
web / src /组件 作者:表示单个作者AuthorForm:用于更改数据字段的实际HTML表单作者显示作者列表NewAuthor呈现表单以创建作者(编辑使用单元格)
脚手架足够酷,可以为我创建一个测试文件,因为Jest是在初始项目中内置的。打开服务/作者/ authors.test.js并删除几个单元测试:
进口{createAuthor,deleteAuthor}从”。/作者的让作者它(“创建作者”,()=>{作者=createAuthor({输入:{的名字:“T”,电子邮件:“xyz@abc.xo”}})})它(“删除作者”,()=>{deleteAuthor(作者)})因为这是与实际数据库对话,所以一定要编写符合实际数据库的测试幂等.这意味着重复运行测试应该没有副作用,也不会在数据库中留下任何坏数据。如果您认为合适,可以随意添加更多测试。
从项目的根目录运行测试:
node_modules。bin /笑话红杉如何处理数据
Redwood使用GraphQL来查询和修改数据。这是一个GraphQL查询在后端所做的事情:

前端使用Apollo Client创建GraphQL有效负载,发送到云中无服务器的AWS Lambda函数。如果您在开发人员工具中查看请求URL,请注意所有有效负载都转到.redwood /功能/ graphql端点。的graphql / authors.sdl.js而且服务/作者/ authors.js文件是公开到Internet的公共API的接口。
开放api / src / graphql / authors.sdl.js揭示了以下GraphQL模式定义:
出口常量模式=gql`类型作者{id:Int!的名字:字符串!电子邮件:字符串!主题:字符串createdAt:DateTime!}类型查询{作者:[作者!]!作者(id:Int!):作者}输入CreateAuthorInput{的名字:字符串!电子邮件:字符串!主题:字符串}输入UpdateAuthorInput{的名字:字符串电子邮件:字符串主题:字符串}类型突变{createAuthor(输入:CreateAuthorInput!):作者!updateAuthor(id:Int!,输入:UpdateAuthorInput!):作者!deleteAuthor(id:Int!):作者!}`这转化为Redwood寻找以下五个解析器:
作者()作者({id})createAuthor(输入{})updateAuthor(输入{id})deleteAuthor ({id})
打开api / src /服务/作者/ author.js,界面如下:
进口{db}从“src / lib / db”出口常量作者=()=>{返回db.作者.findMany()}出口常量作者=({id})=>{返回db.作者.findOne({在哪里:{id},})}出口常量createAuthor=({输入})=>{返回db.作者.创建({数据:输入,})}出口常量updateAuthor=({id,输入})=>{返回db.作者.更新({数据:输入,在哪里:{id},})}出口常量deleteAuthor=({id})=>{返回db.作者.删除({在哪里:{id},})}回头看看我写的单元测试,因为它重用了相同的代码来访问数据库。Redwood允许您重用这些服务,因为它们是单个表之上的抽象。这意味着业务逻辑可以重用尽可能多的服务来完成工作。其中一些功能可以通过GraphQL公开给客户端,也可以不公开。想想authors.sdl.jsGraphQL模式定义作为公开给浏览器的公共接口,以及这个author.js文件作为私有接口。为了证明这一点,编辑SDL文件并使用突变删除任何一行updateAuthor ().下一次GraphQL有效负载请求这一更改时,它会在浏览器中爆炸。很整洁,是吧?
接下来,Redwood使用细胞的概念来告诉成功组件的数据。现在我将深入研究细胞,看看这是什么成功组件是什么以及它做什么。
细胞
好消息是脚手架已经负责创建单元格了。Redwood使用单元格作为数据获取的装饰性方法。每次组件需要来自数据库的数据或任何有延迟的异步调用时都使用单元格。单元导出几个特殊命名的组件,如成功,其余的工作由雷德伍德完成。
红木单元在处理数据时遵循这个生命周期:
- 执行
查询并显示加载组件 - 如果出现错误,则呈现
失败组件 - 如果没有数据(零配置),则呈现
空组件 - 否则,呈现
成功组件
有生命周期助手,比如beforeQuery用于按摩道具前运行查询,afterQuery用于按摩从GraphQL返回的数据。这些帮助程序在数据发送到成功组件。
至少,细胞需要查询而且成功出口。没有一个空组件,结果最终在成功.如果没有失败组件时,错误将显示到浏览器的控制台。
要看牢房,打开web / src /组件/ AuthorCell / AuthorCell.js:
出口常量查询=gql`查询FIND_AUTHOR_BY_ID($ id:Int!){作者:作者(id:$ id){id name电子邮件主题createdAt}}`出口常量加载=()=><div>加载...</div>出口常量空=()=><div>作者没有找到</div>出口常量成功=({作者})=>{返回<作者作者={作者}/>}注意,当页面只有一个作者呈现时,此单元格处理加载、空和成功状态。
最终的想法
总的来说,Redwood还没有准备好生产,但它从JavaScript社区汲取了很多好的概念。React和GraphQL等现代思想使这个框架走上了一条良好的道路。单元格解决了一个常见的React问题,我在获取数据时经常看到这个问题。将GraphQL和Prisma作为私有/公共接口的一等公民使用是很有趣的。作为奖励,我惊喜地发现在后端编写单元测试是多么容易。



